

Can Sentiment Analysis Map a Love Triangle?
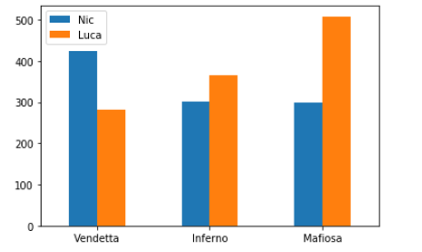
Writer: Roisin O’DonnellThis feature will discuss how sentiment analysis can be used to recreate romantic relationships and obsessions in a narrative.Research question: ‘Can sentiment analysis be used to map the love triangle in Catherine Doyle’s series of novels?’I have chosen the Blood for Blood trilogy because its plot and themes relate to my research question. And sentiment analysis because a love triangle is emotional and will use sentimental words. Performing sentiment analysis would be effective because the story is told in the first person. This means the story would be more personal and the emotional bias of the protagonist would be in the results. It will avoid one of the limitations of third- and second-person narrative mentioned in ‘A Survey on Sentiment and Emotion Analysis for Computational Literary Studies’. In the article it is explained it is ‘not clear how one can distinguish between emotion words used by the author to express their sentiment’.The first task was finding and collecting the dataset. Online resources for the Blood for Blood series were limited due to the series’ small readership and the first book being published five years ago. Full versions of the books in plain text form could be found online.The programming language Python. Plans for the programs that would perform the analysis were sketched out. The project would be broken into two programs. The first program would count the number of times the two love interest’s names appeared in each book. The names Nic and Luca are not listed on any universal positive, negative or neutral word list but they would have sentimental value to the protagonist. If this theory was correct the output of the program would be who she was thinking about the most in each book. It would also show the person she was thinking about the least. The characters' full names, Gianluca and Nicoli, were not included. This decision was made because other characters shared these names and the protagonist, Sophie, never refers to Nic and Luca by these names. If the full names were included it could cause incorrect results.The second program would look for the occurrence of the name Luca or Nic in a sentence. It would tokenise all the sentences that include the chosen name and add it to a list. The list of sentences would then be checked against a list of a hundred positive, negative or neutral words. A hundred words were chosen to keep each word list the same length. The positive, neutral and negative lists included words related to the genre of novel. This led to the addition of crime, mafia and murder to the negative word list. This decision was made because fighting and death scenes are heavily featured in the book. Some phrases in the novels are Italian. Words such as omertà (don’t snitch) were left out despite their significance. I do not understand Italian and there could be a misinterpretation of the Italian data.The program performs what Sarah Steger refers to as a ‘testbed’. An if statement that checks if the sentimental words from the list are present ‘with a classification of “sentimental” or “unsentimental”’. The program then counts the occurrences of the sentimental words and gives a total. Both programs were executed on each book and each character. Jupyter Notebook was used to recreate the initial findings visually.Each novel had a similar length. There is only a 1,000-word difference between Inferno and Mafiosa. Vendetta is the shortest book in the series at 84,168 words. The relative frequency and the initial figures had an insignificant difference between each other. Relative frequency was calculated because each book in the series was focused on individually.The name occurrence methodology showed a clear pattern. In the first book, Vendetta, Nic has the highest name count. His name is mentioned 0.504% of the time. Luca’s relative frequency was 0.335%. In the second book in the series, Inferno, Nic and Luca’s name count results are even. Luca occurs in 0.382% of the novel and Nic occurs 0.315%. However, in the final book, Mafiosa, Nic’s name count remains about the same as in Inferno at 0.315%. The count of Luca is higher than Nic’s name count has ever been in the series. It has a relative frequency of 0.535%. The results using a sentimental word list produced different results. A pattern that emerged in the dataset was the name with the highest positive count had the highest negative count. This was not an expected result. In Vendetta, Nic had 0.165% positive associations with his name in the dataset. This is the highest. Luca had significantly lower, with 0.060% mentions in Vendetta. Luca had higher negative than positive matches with the sentimental word list. But Nic had the highest negative matches despite being the most positively associated with in the narrative.Like the name occurrences, in Inferno the sentiment analysis showed smaller differences between results. The pattern of the person with the highest positive count having the most negative count continued. With Luca scoring the highest positive and negative occurrences. He was mentioned positively 0.079% of the time and negatively 0.093% of the time. Nic’s results dropped significantly. He had a positive frequency of 0.070% in Inferno. He had a negative relative frequency of 0.072%.In Mafiosa, Luca’s results show he received more neutral mentions than Nic. Nic achieved 0.0210% of neutral mentions and Luca received 0.048%. Following the pattern from the results of the other books, Luca’s sentences matched with the positive word list and the negative word list the most. In Mafiosa, his positive and negative analysis results are close to each other. At a relative frequency, his positive and negative results are 0.135% and 0.137%. It is a dramatic difference between Luca’s results in Inferno and VendettaHowever, Nic in Vendetta has the overall the highest occurrence of positive association by around 0.03%.Sara Steger says on sentiment analysis, ‘sentimentality should carry its pattern close to the surface’. In my dataset this was subjective. This is because of the violence and brutality featured in the plot of the series. It makes the pattern between negative and positive sentiment a challenge to interpret. This was especially true for the final book where major action and character deaths occur. It makes it hard to gauge how much of the negativity is directed at the love interests. In any romance book it is expected that the least negative words would be associated with the love interest. The ‘pattern close to the surface’ can instead be seen more clearly in the name counts.The name counts show the real course of the story. In the first book, Nic is Sophie’s love interest. In several scenes he is shown to be especially kind to Sophie and interested in her romantically. Luca is presented as the enemy. He mocks Sophie on several occasions and only features in the story when Nic is present. The name counts support this interpretation. It shows Nic has more occurrences than Luca. In the second book, Inferno, Sophie has feelings for both boys. She struggles to choose between them. The name counts show she thinks back and forth between the two of them. In the third book, Mafiosa, Luca is shown as Sophie’s boyfriend whereas Nic is painted as an enemy. The story shifts its focus to Luca and Sophie’s relationship and trials. The name counter shows Luca’s increased presence in the story and Nic’s decreasing presence.The most positive mentions in the series belong to Nic in Vendetta. This is strange and unexpected because he is not the love interest Sophie chooses at the end of the series. This shows that Vendetta is the happiest novel in the series. The dataset’s narrative gets darker as the series progresses. This is seen in the rise in the relative frequency of negative associations. This is probably because in Vendetta Sophie is ignorant of the mafia and the type of lives her love interests live. Sophie does not experience much fear in this novel. However, there is an exception at the end of the novel. A gang fight breaks out and Sophie uses her body to shield a wounded Luca from the gun fire. In comparison, in the two following novels feature Sophie’s mother dying in a fire and Sophie being shot in a failed assassination attempt.The sentiment analysis results show Vendetta is her happiest time in the series. Vendetta has the highest positive sentiment analysis result. It could be debated whether this is her happiest time because Sophie is not in a relationship with Luca at this point in the series.It is possible, according to the results, that Sophie’s time at the beginning of the series with Nic was her happiest time in the love triangle. The results also show that Luca’s name has more sentimental value to Sophie than Nic’s has ever had. An overall analysis shows that Luca has been mentioned and thought about more than Nic.There is a 0.03% difference in relative frequency between Luca’s final name count and Nic’s first name count. This could suggest in the final book she cared more for Luca than Nic. The negative and positive analysis also shows Sophie seeing Luca as a partner. She experiences positive and negative associations with him. This could indicate she trusts him and works as a team with him.The results also show the problematic aspects to the novel. At the beginning of the project I reflected on the book series. I had theorised Sophie’s relationships with Nic and Luca are not healthy. In the first book Luca, hits Sophie in the face with a basketball and laughs when she is injured. When Sophie meets Nic he chases her and knocks her down. Because of the crime bases of the novel, it is not possible with sentiment analysis to figure out how common these occurrences are. And, how negatively they influence Sophie’s relationship with the pair.The limitations and affordances of sentiment analysis were important to consider when making an interpretation of this dataset. It was equally important to consider the context of the results. The context helped me expand on the patterns that were revealed in the results.To end this answered research question, I believe my methodology and the results it yielded answered my research question in the most effective way. The limitations such as collecting the dataset were overcome. Ultimately the use of visualisation techniques such as bar charts and line graphs successfully remapped Catherine Doyle’s Blood for Blood series. Additionally, it created more research questions. Such as how healthy were the relationships and how much the genre of the series interfered with the results. And overall, it answered theories and provided figures to match those theories.